Sentiment Analysis of a CHILDES Corpus
CS 631 Final Project, part 2
Grace Lawley
August 14th, 2018
The Dataset
The Dataset
- Child Language Data Exchange System (CHILDES)
The Dataset
Child Language Data Exchange System (CHILDES)
- Online repository of language acquisition data
The Dataset
Child Language Data Exchange System (CHILDES)
Online repository of language acquisition data
Used to study language development, second language acquisition, child directed speech
The Dataset
Child Language Data Exchange System (CHILDES)
Online repository of language acquisition data
Used to study language development, second language acquisition, child directed speech
Why is CHILDES special?
The Dataset
Child Language Data Exchange System (CHILDES)
Online repository of language acquisition data
Used to study language development, second language acquisition, child directed speech
Why is CHILDES special?
- Corpora of children speaking North American English are very hard to come by
The Dataset
- CHILDES → Eng-NA → Kuczaj Corpus
The Dataset
CHILDES → Eng-NA → Kuczaj Corpus
Longitudional Case Study
1 target child: Abe
~2 - ~5 years old
210 transcripts (average of 810 words long)
The Raw Data
- Pulled raw utterances data down from the CHILDES database with the
childesrpackage
The Raw Data
Pulled raw utterances data down from the CHILDES database with the
childesrpackageSome raw utterances:
The Raw Data
Pulled raw utterances data down from the CHILDES database with the
childesrpackageSome raw utterances:
## [1] "okay that's a alligator he got a cigar"## [2] "go away" ## [3] "camel pig and the donkey" ## [4] "you go away" ## [5] "uhhuh eat" ## [6] "oh no"The Raw Data
Pulled raw utterances data down from the CHILDES database with the
childesrpackageSome raw utterances:
## [1] "okay that's a alligator he got a cigar"## [2] "go away" ## [3] "camel pig and the donkey" ## [4] "you go away" ## [5] "uhhuh eat" ## [6] "oh no"- Cleaned, processed, & tokenized the data
The Sentiment Analysis
The Sentiment Analysis
- Used the
nrcWord-Emotion Association Lexicon in thetidytextpackage
The Sentiment Analysis
Used the
nrcWord-Emotion Association Lexicon in thetidytextpackageClassifies words into 10 different sentiment categories:
- anger
- disgust
- fear
- joy
- negative
- sadness
- anticipation
- surprise
- trust
- positive
The Sentiment Analysis
Used the
nrcWord-Emotion Association Lexicon in thetidytextpackageClassifies words into 10 different sentiment categories:
- anger
- disgust
- fear
- joy
- negative
- sadness
- anticipation
- surprise
- trust
- positive
- Merged with tokens with
dplyr::inner_join()
The Sentiment Analysis
Used the
nrcWord-Emotion Association Lexicon in thetidytextpackageClassifies words into 10 different sentiment categories:
- anger
- disgust
- fear
- joy
- negative
- sadness
- anticipation
- surprise
- trust
- positive
Merged with tokens with
dplyr::inner_join()- Only kept tokens that occured in both dataframes
Six sentiments
Six sentiments
Positive
trust
joy
anticipation
Six sentiments
Positive
trust
joy
anticipation
Negative
sadness
fear
anger
The Original Plot
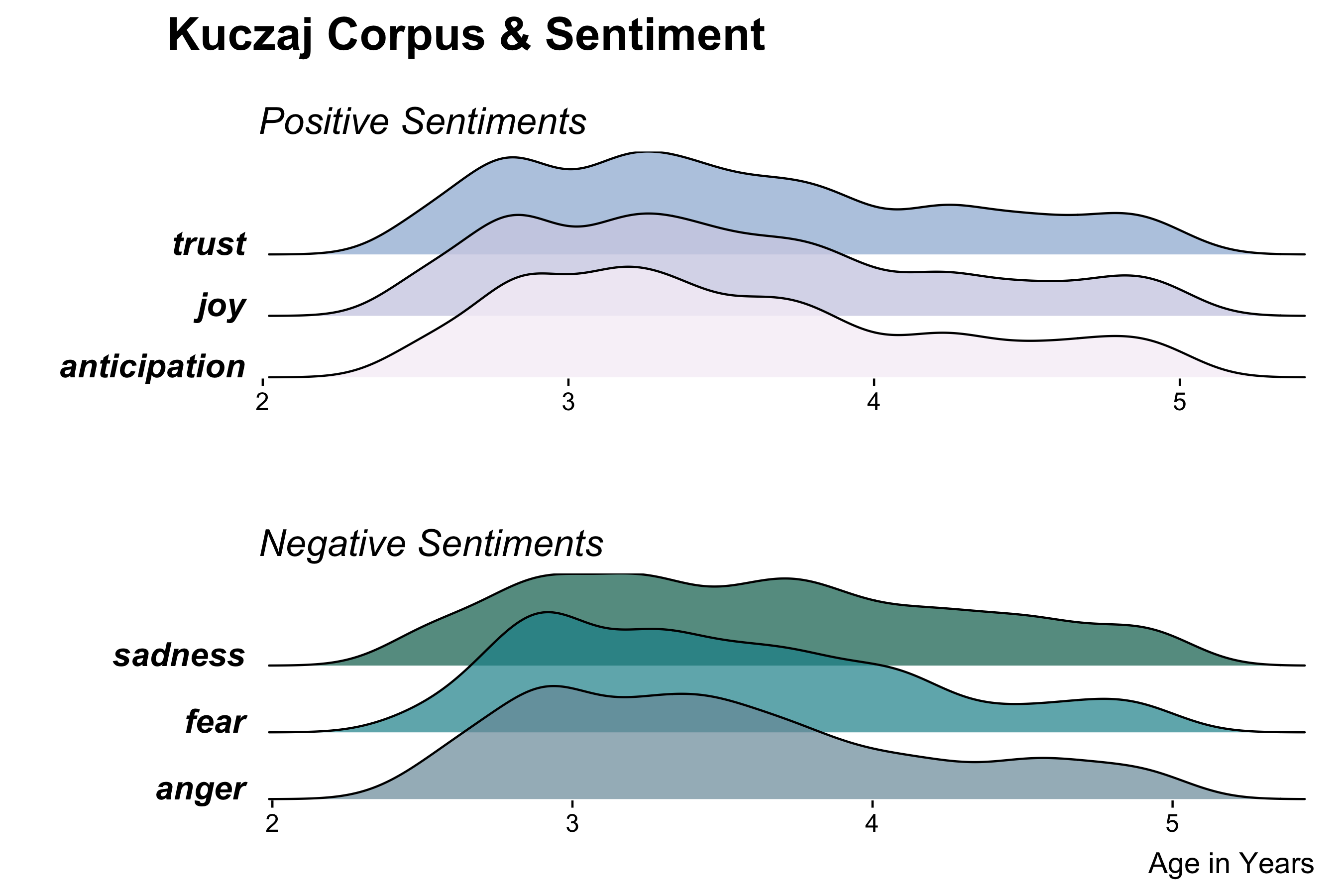
Problems
Problems
- Visualization is difficult to explain
Problems
Visualization is difficult to explain
~86% of tokens were lost when filtering against the NRC Word-Emotion Association Lexicon
Problems
Visualization is difficult to explain
~86% of tokens were lost when filtering against the NRC Word-Emotion Association Lexicon
Transcript length varies a lot
Problems
Visualization is difficult to explain
~86% of tokens were lost when filtering against the NRC Word-Emotion Association Lexicon
Transcript length varies a lot
Distribution of transcripts across the ages varies a lot
Problems
Visualization is difficult to explain
~86% of tokens were lost when filtering against the NRC Word-Emotion Association Lexicon
Transcript length varies a lot
Distribution of transcripts across the ages varies a lot
Normalization
Binned age into months:
30.13204,30.19775,30.32916,...30.59200→30
Normalization
Binned age into months:
30.13204,30.19775,30.32916,...30.59200→30
- For each age bin and each sentiment:
Normalization
Binned age into months:
30.13204,30.19775,30.32916,...30.59200→30
For each age bin and each sentiment:
n_percent = n_sentiment/n_tokens
Normalization
Binned age into months:
30.13204,30.19775,30.32916,...30.59200→30
For each age bin and each sentiment:
n_percent = n_sentiment/n_tokens
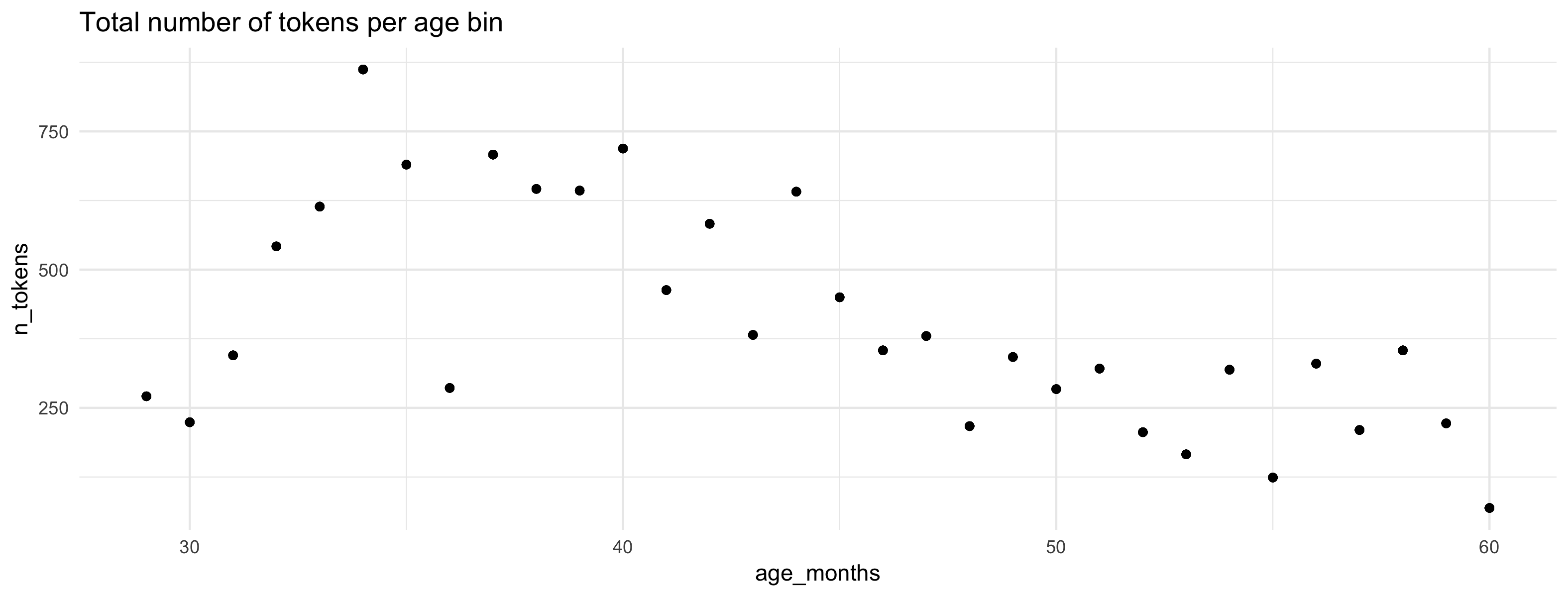
Iterate!
Version 1
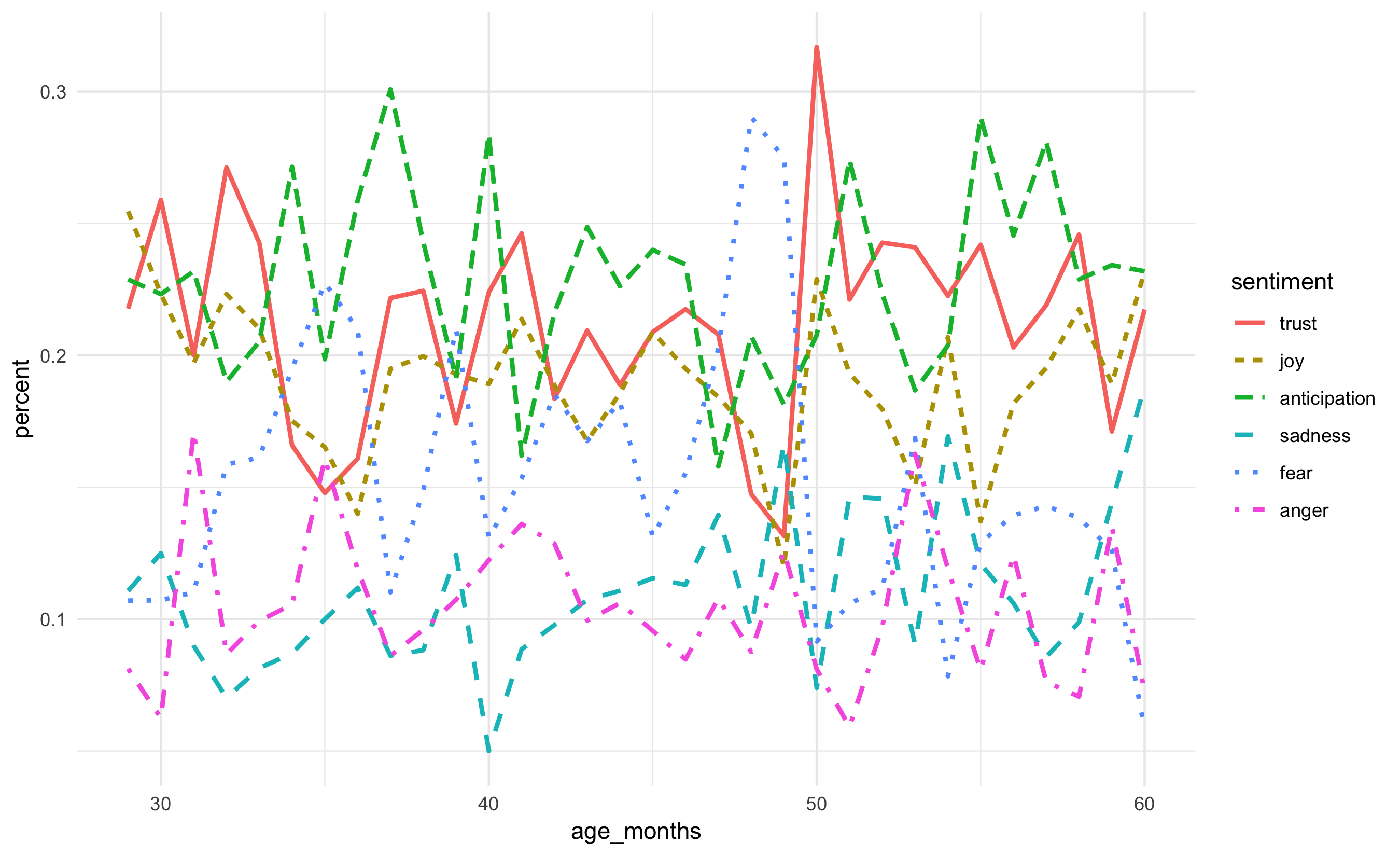
Version 2
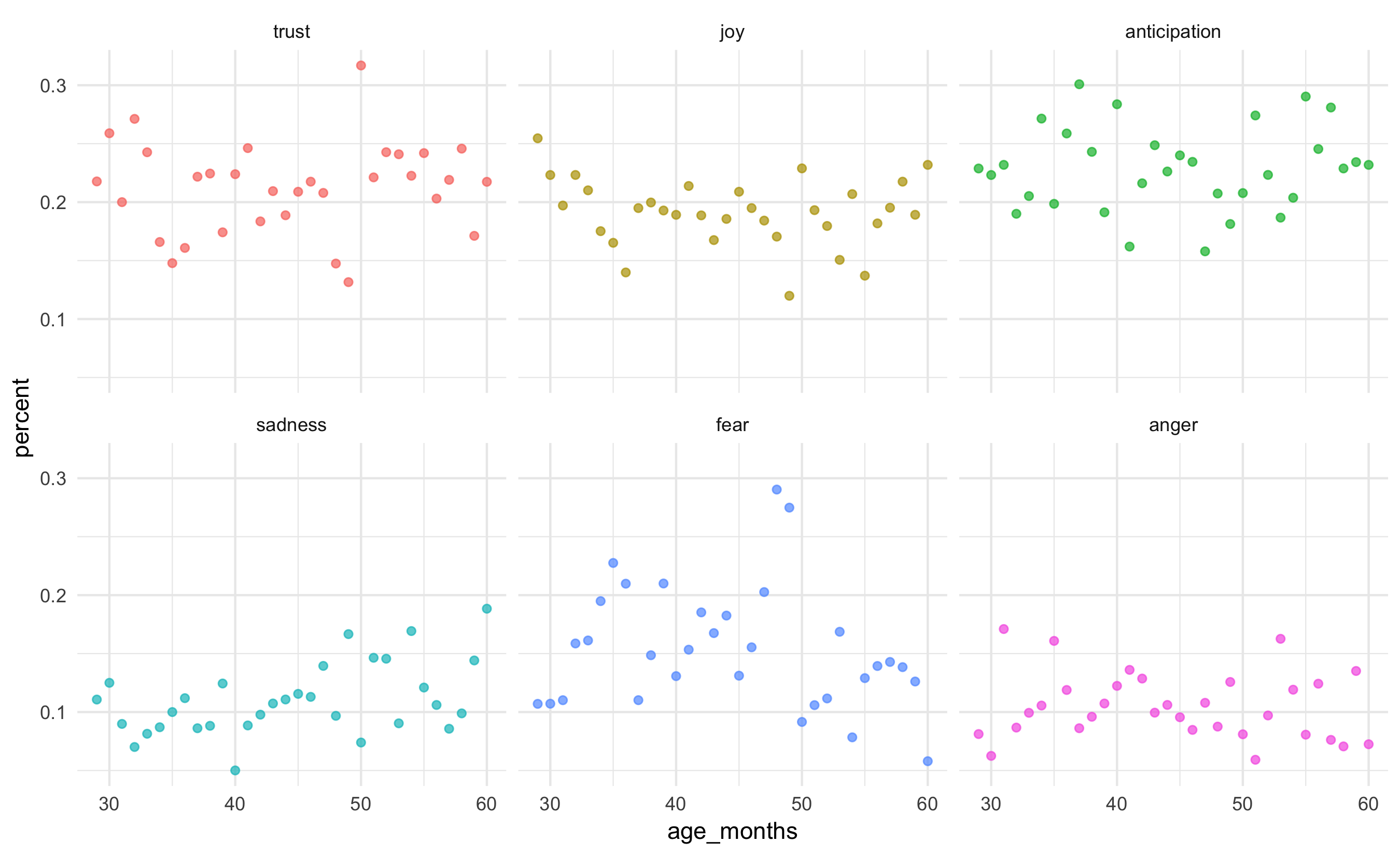
Version 3
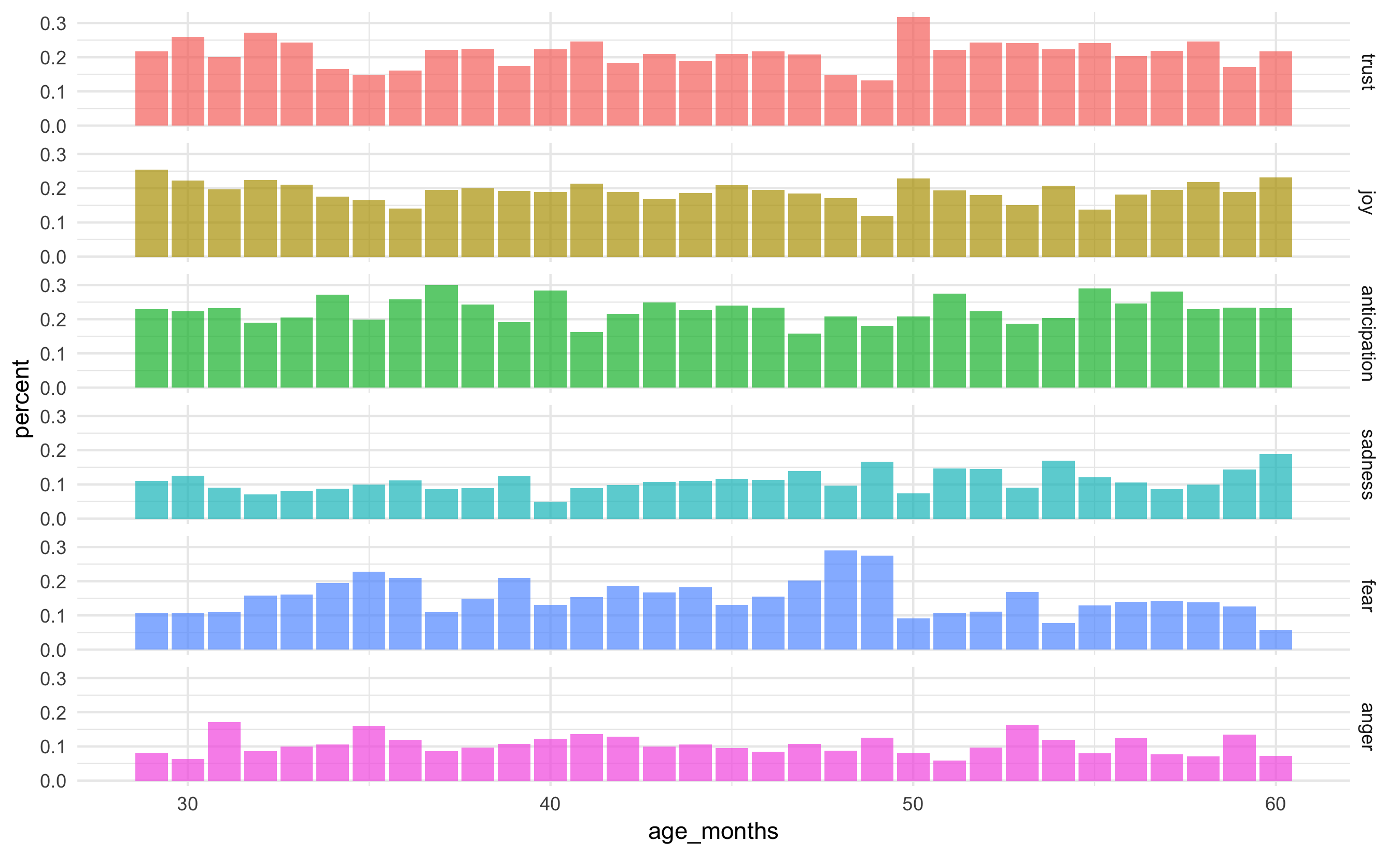
Version 4
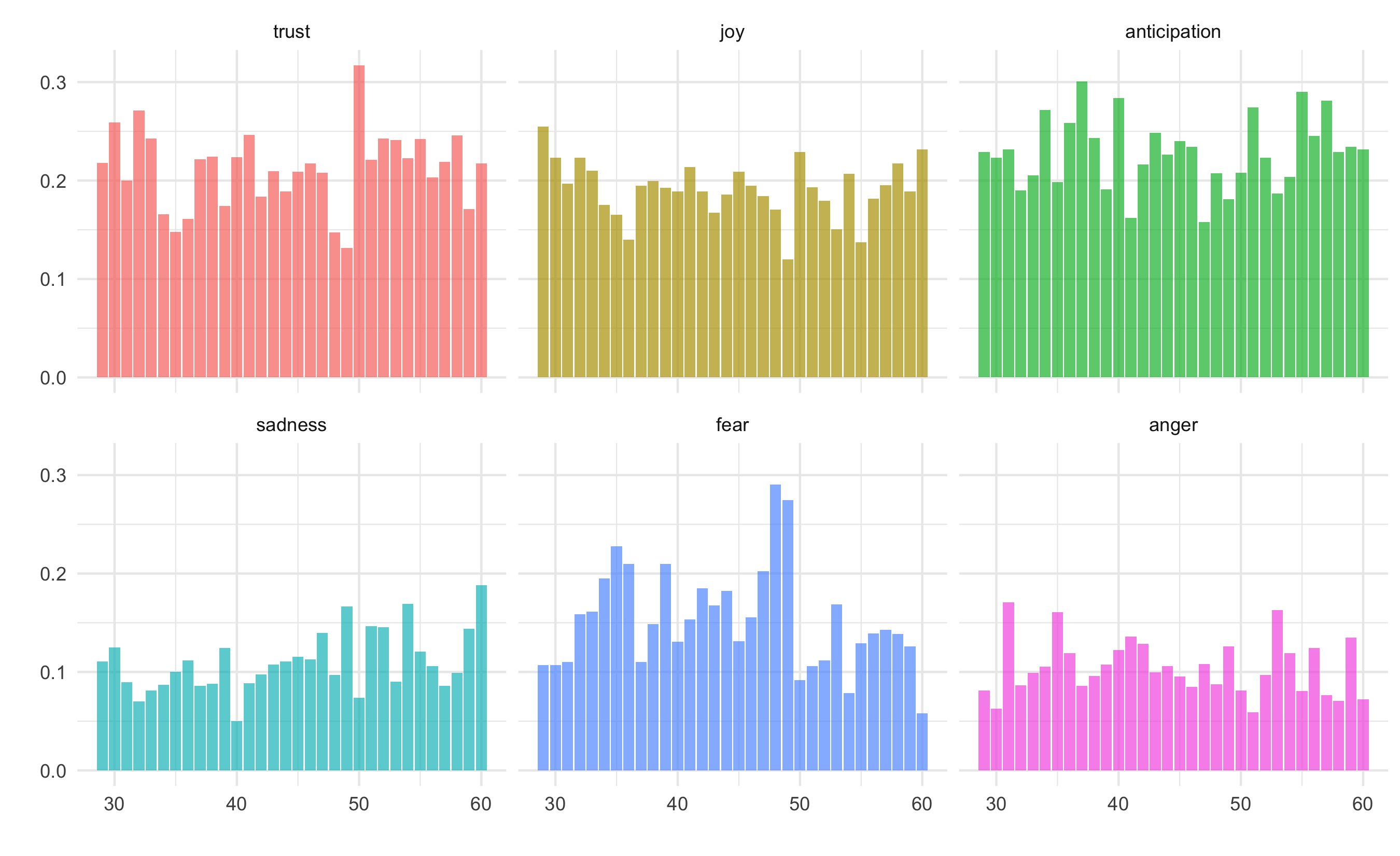
Version 5
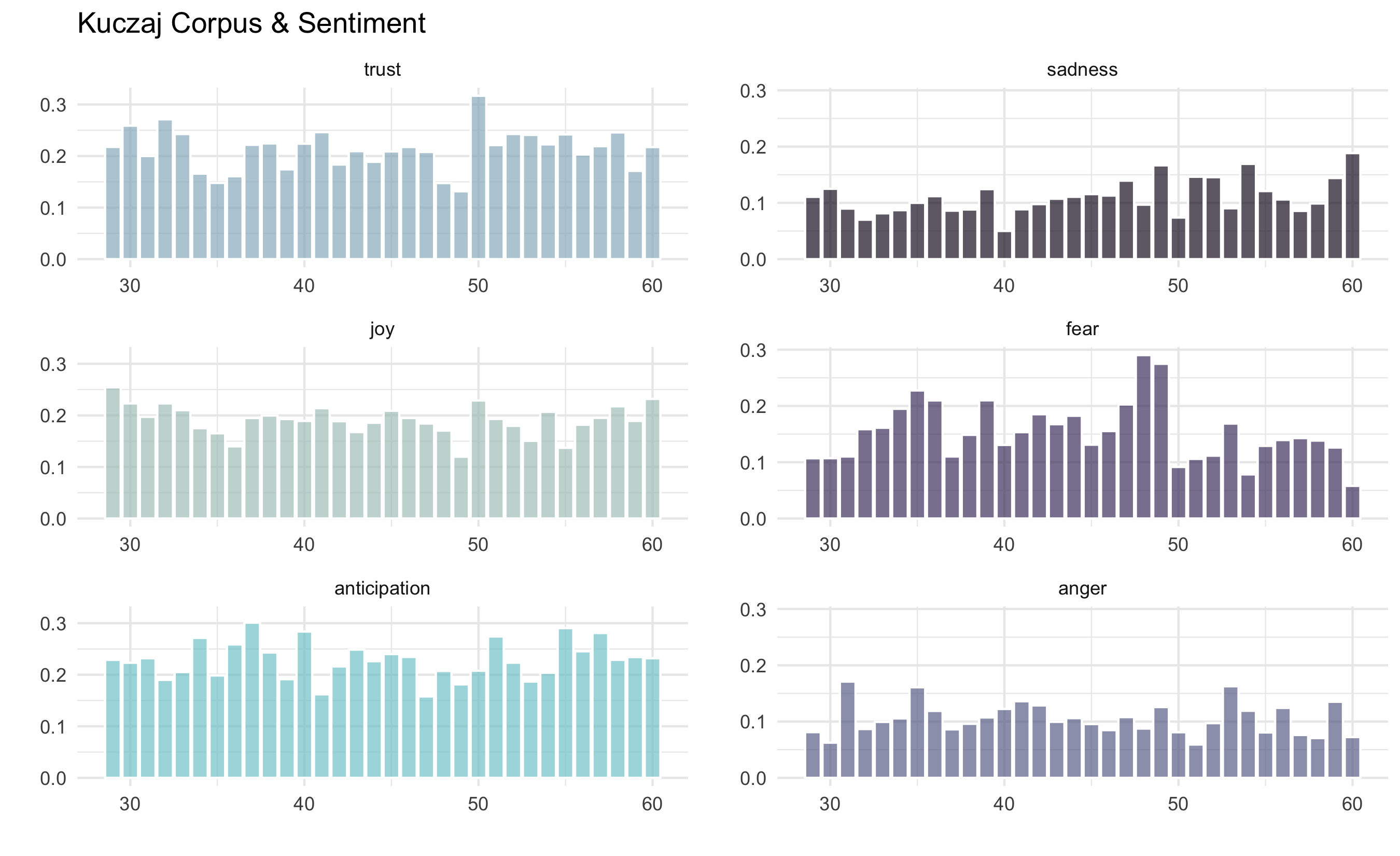
Version 5.1
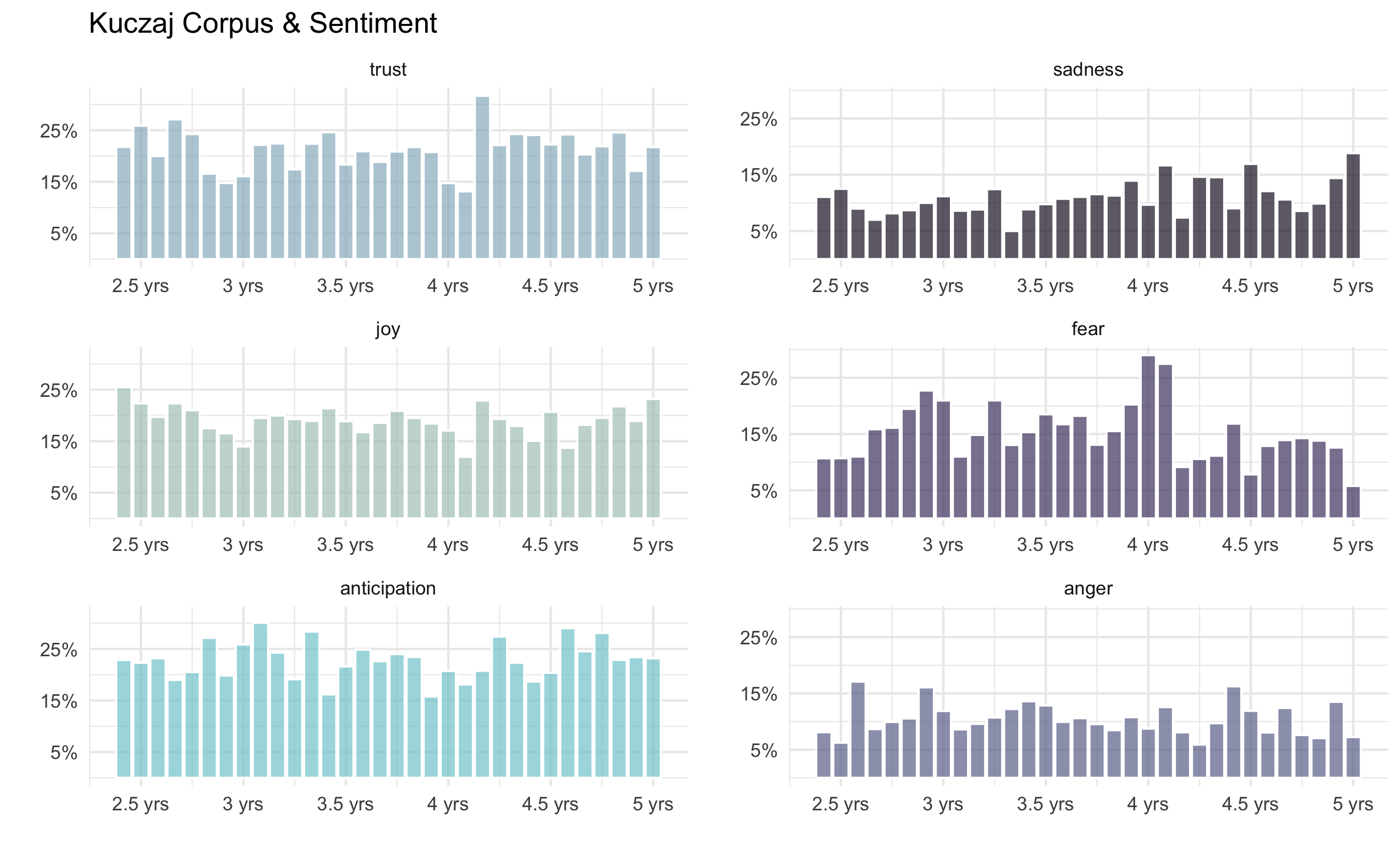
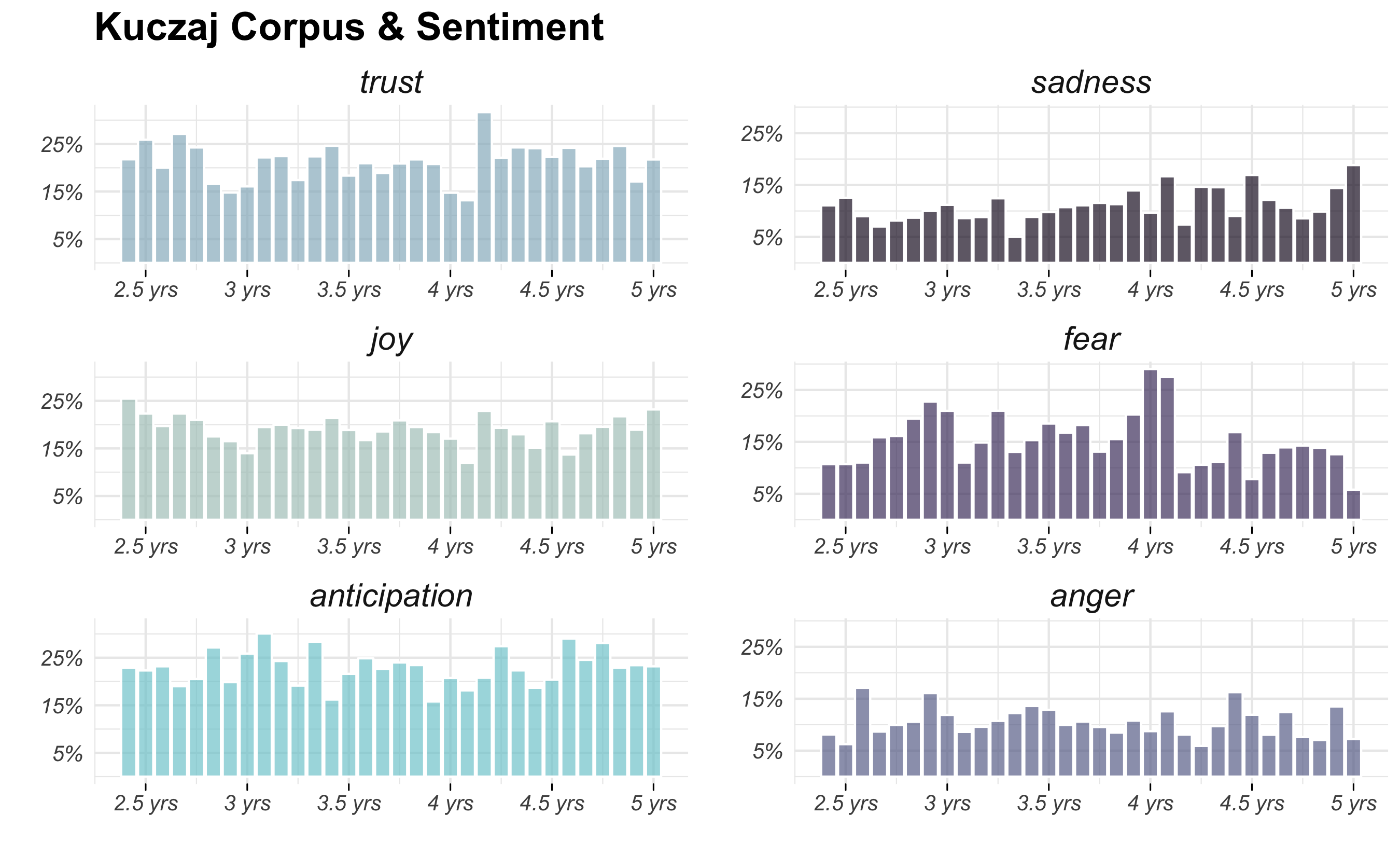
The Final Version
The Final Version
Thank you!
Github Repository:
gracelawley/kuczaj-corpus
Write up & code available at:
grace.rbind.io/project/kuczaj_pt2/
Slides made with the R package xaringan
These slides - rendered & raw
Based on my CS 631 Final Visualization Project
Write up & code available at:
grace.rbind.io/project/final_vis/